De acordo com as Leis 12.965/2014 e 13.709/2018, que regulam o uso da Internet e o tratamento de dados pessoais no Brasil, ao me inscrever na newsletter do portal DICAS-L, autorizo o envio de notificações por e-mail ou outros meios e declaro estar ciente e concordar com seus Termos de Uso e Política de Privacidade.
Formatando strings multibyte com printf
Colaboração: Paulo Roberto Bagatini
Data de Publicação: 9 de junho de 2024
Tenho um projeto em shell chamado shellect (http://gitlab.com/arkanon/bash/shellect) onde me deparei com a necessidade de alinhar verticalmente caracteres quando as linhas possuem caracteres multibyte, como ó ou 🤓, por exemplo.
Apesar de ser um tanto improvável encontrar caracteres assim em um nome de diretório no Unix/Linux/BSD (ainda que tecnicamente possível), vou usar isso como desculpa para introduzir o assunto.
Começamos garantindo que temos instalada uma fonte monoespaçada com emojis gráficos que será (ou pelo menos espera-se que seja) usada pelo terminal. Se ainda não estava, após instalada pode ser necessário reiniciar o terminal.
$ sudo apt install fonts-noto-color-emoji
Vamos lá:
$ mkdir multibyte $ cd multibyte $ mkdir ó 🤓 $ LANG=pt_BR.utf8 ls -1 ó 🤓 $ LANG=C ls -1 ''$'\303\263' ''$'\360\237\244\223' $ LANG=C ls -1 --quoting-style=shell ?? ???? $ LANG=C ls -1 --quoting-style=shell --show-control-chars ó 🤓 $ LANG=C ls -1 --quoting-style=escape \303\263 \360\237\244\223 $ estilos='literal locale shell shell-always shell-escape shell-escape-always c escape' $ dir=ó $ for i in $estilos; { printf ' %-21s' $i; LANG=C ls -d --quoting-style=$i $dir; } literal ?? locale '\303\263' shell ?? shell-always '??' shell-escape ''$'\303\263' shell-escape-always ''$'\303\263' c "\303\263" escape \303\263
Na listagem acima vemos “coisas estranhas”.
Em locale pt_BR.utf8, tudo certo. O “problema” aparece em locale C, que não suporta UTF-8 e portanto a codificação das strings acaba sendo apresentada como uma sequência de números octais, que é uma forma possível para ele representar os caracteres na codificação original (UTF-8). Listando em estilo shell, vemos duas interrogações no diretório ó e 4 no 🤓. Adicionando o parâmetro --show-control-chars voltamos a ver os caracteres corretamente, mas ainda percebe-se que o ó ocupa uma coluna na tela enquanto o 🤓 ocupa duas.
Por quê?
Criamos um vetor com alguma strings que ocupam visualmente a mesma quantidade de colunas na tela em fonte monoespaçada:
$ multibyte=(
'oo oo'
'oo oó'
'oo óó'
'oo o✓'
'oo 🤓'
'oó óó'
'óó óó'
'óó 🤓'
'🤓 🤓'
)
A primeira observação é que o caractere 🤓 DE FATO ocupa duas colunas. O Unicode, ao estender o conjunto de caracteres ASCII, abrangeu classes que exigem mais espaço físico para serem impressos.
Agora observamos o resultado de um loop que utiliza o printf para deixar todas as strings do vetor com 11 colunas de largura:
$ set "${multibyte[@]}"
$ for i; { printf "(%-11s)\n" "$i"; }
(oo oo )
(oo oó )
(oo óó )
(oo o✓ )
(oo 🤓 )
(oó óó )
(óó óó )
(óó 🤓 )
(🤓 🤓 )
Só a primeira string, formada apenas por o’s minúsculos não acentuados, teve o resultado esperado. As outras formaram um carnaval de desalinhamento… 🫤
Como o printf leva em consideração apenas a quantidade de bytes das strings na formatação %[N]s, usá-lo com base apenas na quantidade de colunas desejadas é inefetivo para formatação de strings unicode. Esse comportamento com caracteres multibyte pode ser considerado um pequeno pesadelo: cada linha é retornada com um padding diferente e aparentemente aleatório de espaços em branco, apesar da “largura” na tela ser a mesma.
Mas existe uma forma bastante razoável de resolver isso em shell.
Vamos analisar essas várias strings com o comando wc:
$ wc --help | grep [mcL],
-c, --bytes mostra a quantidade de bytes
-m, --chars mostra a quantidade de caracteres
-L, --max-line-length emite o comprimento da linha mais longa
$ for i
{
read m c L <<< $(printf "$i" | wc -mcL)
printf "%s %2s %s (%-11s)\n" $m $c $L "$i"
}
6 6 6 (oo oo )
6 7 6 (oo oó )
6 8 6 (oo óó )
6 8 6 (oo o✓ )
5 8 6 (oo 🤓 )
6 9 6 (oó óó )
6 10 6 (óó óó )
5 10 6 (óó 🤓 )
4 10 6 (🤓 🤓 )
A terceira coluna da saída, resultado do parâmetro -L do wc, mostra que as strings ocupam visualmente a mesma quantidade de colunas no terminal, apesar de formadas por quantidades diferentes de caracteres (primeira coluna, parâmetro -m). A diferença entre elas, estruturalmente falando, é a quantidades de bytes (caracteres ASCII propriamente ditos) que cada uma ocupa, como mostra a segunda coluna, do parâmetro -c.
Podemos “ver” a estrutura desses caracteres. Eles podem ser entendidos como uma sequencia de caracteres ASCII…
$ printf o | od -An -tx1 6f $ echo -e '\x6f' o $ printf ó | od -An -tx1 c3 b3 $ echo -e '\xc3\xb3' ó $ printf ✓ | od -An -tx1 e2 9c 93 $ echo -e '\xe2\x9c\x93' ✓ $ printf 🤓 | od -An -tx1 f0 9f a4 93 $ echo -e '\xf0\x9f\xa4\x93' 🤓
… ou caracteres propriamente ditos na codificação Unicode; no exemplo abaixo, de 32 bits (4 bytes):
$ printf o | iconv -t UTF-32LE | od -An -tx4 0000006f $ echo -e '\U6f' o $ printf ó | iconv -t UTF-32LE | od -An -tx4 000000f3 $ echo -e '\Uf3' ó $ printf ✓ | iconv -t UTF-32LE | od -An -tx4 00002713 $ echo -e '\U2713' ✓ $ printf 🤓 | iconv -t UTF-32LE | od -An -tx4 0001f913 $ echo -e '\U1f913' 🤓
O pulo do gato, então, é perceber que o erro da formatação do printf pode ser compensado adicionando ao valor da largura desejada (11), a diferença entre a quantidade de bytes que forma a string (dada pelo -c do wc) e a quantidade de colunas do terminal que a string ocupa (dada pelo -L):
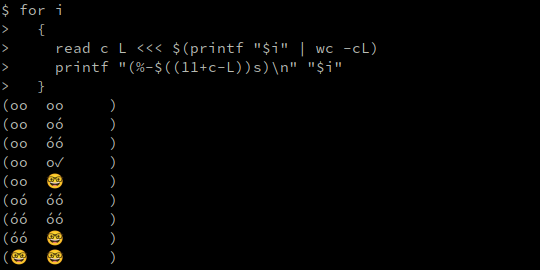
$ for i
{
read c L <<< $(printf "$i" | wc -cL)
printf "(%-$((11+c-L))s)\n" "$i"
}
(oo oo )
(oo oó )
(oo óó )
(oo o✓ )
(oo 🤓 )
(oó óó )
(óó óó )
(óó 🤓 )
(🤓 🤓 )
Talvez na tela que você esteja lendo esse texto o alinhamento dos ) acima não seja perfeito, mas isso é devido à renderização do seu software. Num terminal texto eles ficarão perfeitamente alinhados na vertical:
Um pouco de água fria
Para nossa tristeza, enquanto alguns caracteres ocupam 2 colunas para serem mostrados e os programas identificam isso, outros precisam de mais mas isso é ignorado.
O caractere ﷽ (Basmala, expressão árabe que significa “Em nome de Deus, o Mais Gracioso, o Mais Misericordioso”), por exemplo, mesmo também sendo codificado em 4 bytes (\U0000fdfd) precisa 12 (doze!) colunas na tela, mas tanto o wc quanto o terminal reconhecem apenas 1.

É bem provável que os sistemas de renderização de texto que usamos para ler esse texto apresentem adequadamente o caractere mesmo em fonte monoespaçada:
$ printf '1234567890123\n﷽\n' 1234567890123 ﷽ $ printf '﷽' | wc -cL 3 1 $ i=﷽🤓 $ read c L <<< $(printf "$i" | wc -cL) $ printf "(%-$((11+c-L))s)\n" "$i" (﷽🤓 )
Mas por enquanto, o que conseguimos na maioria dos terminais e editores de texto é algo como:
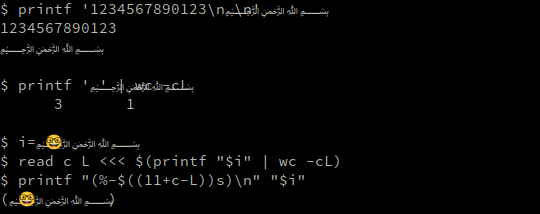
Essa idiossincrasia está relacionada à incapacidade do software de manipular as características gráficas dos caracteres unicode mais novos. Assim como os caracteres que exigem 2 colunas antigamente ficavam mal representados no terminal e alguns editores de código, eventualmente os que exigem 3 ou mais colunas virão a ser adequadamente representados em algum momento futuro. Até lá, o printf vai continuar apresentando resultados inconsistentes se algum deles estiver presente na string a ser formatada…
Referências
- O que é UTF-8, UTF-16, UTF-32?
- O mínimo absoluto que todo desenvolvedor de software deve saber absolutamente e positivamente sobre Unicode e conjuntos de caracteres (sem desculpas!)
- UTF-8 4-byte Character Chart
- Unicode Character “﷽” (U+FDFD)
Comandos usados nesse artigo
Adicionar comentário
This policy contains information about your privacy. By posting, you are declaring that you understand this policy:
- Your name, rating, website address, town, country, state and comment will be publicly displayed if entered.
- Aside from the data entered into these form fields, other stored data about your comment will include:
- Your IP address (not displayed)
- The time/date of your submission (displayed)
- Your email address will not be shared. It is collected for only two reasons:
- Administrative purposes, should a need to contact you arise.
- To inform you of new comments, should you subscribe to receive notifications.
- A cookie may be set on your computer. This is used to remember your inputs. It will expire by itself.
This policy is subject to change at any time and without notice.
These terms and conditions contain rules about posting comments. By submitting a comment, you are declaring that you agree with these rules:
- Although the administrator will attempt to moderate comments, it is impossible for every comment to have been moderated at any given time.
- You acknowledge that all comments express the views and opinions of the original author and not those of the administrator.
- You agree not to post any material which is knowingly false, obscene, hateful, threatening, harassing or invasive of a person's privacy.
- The administrator has the right to edit, move or remove any comment for any reason and without notice.
Failure to comply with these rules may result in being banned from submitting further comments.
These terms and conditions are subject to change at any time and without notice.
Comentários